


published in Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2017
Miguel Bautista
Ekaterina Sutter
Prof. Björn Ommer
Cite as: Bibtex

Abstract:
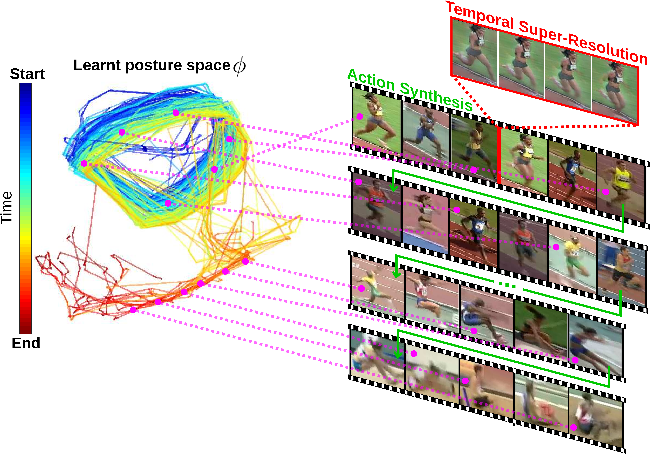
Understanding human activity and being able to explain it in detail surpasses mere action classification by far in both complexity and value. The challenge is thus to describe an activity on the basis of its most fundamental constituents, the individual postures and their distinctive transitions. Supervised learning of such a fine-grained representation based on elementary poses is very tedious and does not scale. Therefore, we propose a completely unsupervised deep learning procedure based solely on video sequences, which starts from scratch without requiring pre-trained networks, predefined body models, or keypoints. A combinatorial sequence matching algorithm proposes relations between frames from subsets of the training data, while a CNN is reconciling the transitivity conflicts of the different subsets to learn a single concerted pose embedding despite changes in appearance across sequences. Without any manual annotation, the model learns a structured representation of postures and their temporal development. The model not only enables retrieval of similar postures but also temporal super-resolution. Additionally, based on a recurrent formulation, next frames can be synthesized.Authors:
Timo MilbichMiguel Bautista
Ekaterina Sutter
Prof. Björn Ommer
Download:
Paper: Arxiv, OtherCite as: Bibtex
Poster:
Applications:
Visualizing Activity Spaces
Temporal Superresolution
Action Synthesis