


Object detection is a difficult problem in computer vision because of very large intra-class variability, object articulation and view-point dependence. However, detecting abnormal objects in videos is even harder because of an enormous number of ways for an object to appear or behave abnormally. The main issue here is how to find abnormal objects if we don't know what we are searching for?
Contrary to the recent trends in abnormality detection in which local image patches are classified individually, we propose a novel approach based on video parsing. We parse each video frame by establishing a set of object hypotheses that jointly explain all the foreground while simultaneously trying to find normal training examples that explain the hypotheses. A hypothesis that is necessary to explain the foreground, but doesn't match any of the training examples is considered abnormal. By parsing the scene and jointly inferring all required object hypotheses we indirectly discover abnormal objects in the scene without knowing in advance what to look for. The illustration of the joint inference process in our video parsing method is shown in Figure 1.
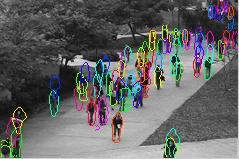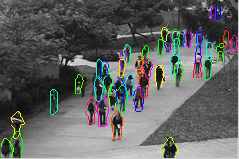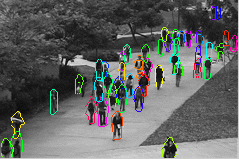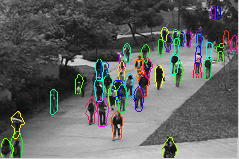
In a typical application scenario, such as video surveillance, videos are recorded by a stationary camera which makes it possible to detect foreground pixels by background subtraction. We also compute the optical flow features that express local behavior of an object. Our video parsing method follows a two-stage approach. In the first stage, we create a shortlist of object hypotheses by evaluating a simple appearance-based classifier on candidate object hypotheses in the foreground. By setting the classifier to have a high recall and low precision, we retain a moderate number of hypotheses (on the order of 10 to 100) without losing any relevant ones. The result of this is shown in Figure 2, together with foreground and optical flow features computed in the preprocessing stage.

In the second stage we parse the scene by selecting a subset of hypotheses from the shortlist that explains the entire foreground, and can additionally be explained using the object model that is learned during training. We use a nonparametric object model obtained by sampling normal objects from the training videos that is depicted in Figure 3.

The activation/deactivation of candidate hypotheses and their explanation with the object model have to be solved jointly for all hypotheses since they are mutually competing. The combinatorial nature of the hypotheses selection problem makes the underlying optimization very difficult and we alternatively solve it. The inference process in our parsing method exploits the explaining-away property described in the statistical literature. In a nutshell, if two hypotheses explain the same part of the foreground, then activation of one hypotheses actually decreases the chances of another hypothesis being active. This property is used by our inference method to deactivate superfluous hypotheses and retain only those hypotheses that are truly necessary for explaining the scene. Figure 4 summarizes our parsing approach.

We evaluate our parsing approach on the UCSD Anomaly Detection Dataset. This state-of-the-art benchmark for abnormality detection has been recently proposed by Mahadevan et al. Abnormalities in the dataset are not staged but consist of unusual objects (e.g. cars on walkways) or unusual behavior (e.g. people cycling across walkways). The training videos contain only normal objects, whereas in the test videos both normal and abnormal instances appear. To extend future utility of the dataset, we completed the pixel-wise ground truth annotation that was previously given only for a subset of test videos, and it can be downloaded from this web page.

Figures 5 and 6 illustrate the abnormality detection results of our video parsing method in two characteristic cases: abnormal objects and abnormal behavior. In Figure 5, the presence of a van on the street that normally features only pedestrians in training videos is recognized as abnormal. The left image shows the set of initial hypotheses (after shortlisting), center left image shows the hypotheses that remain after parsing, center right image shows the abnormality score computed for all foreground pixels and right image depicts the result of matching the active object hypotheses to the object model. Figure 6 shows a video that features only persons, but who are performing various kinds of activities. Some of these activities, such as cycling, running or walking on grass, normally do not occur (they don't exist in the training videos), and therefore are considered here abnormal.

In Figure 7, we directly compare the results of our video parsing approach to MDT method recently proposed by Mahadevan et al. that is the state-of-the-art in the field.
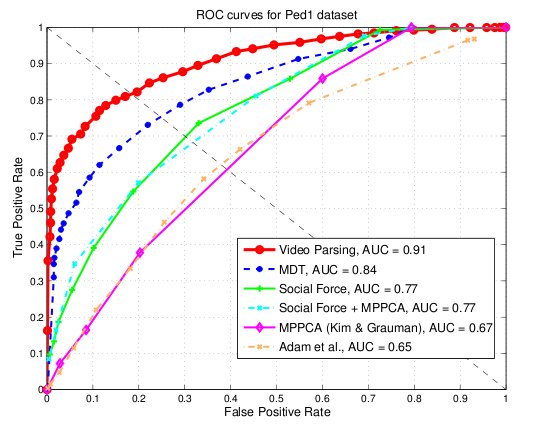
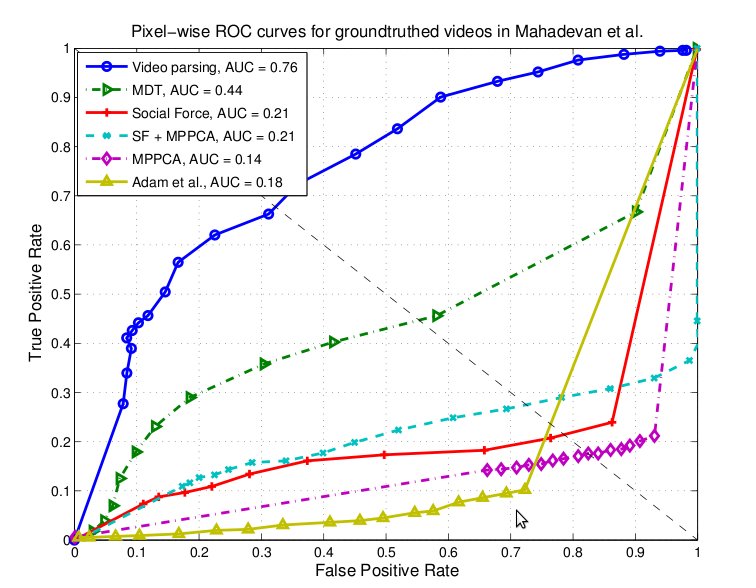
We quantitatively evaluate our video parsing method using two performance metrics: abnormality detection on a frame level and pixel-accurate detection. Left plot in Figure 8 shows the Receiver Operating Characteristic (ROC) for the frame-wise detection, where a frame is labeled as abnormal if it contains one or more abnormalities. We achieve an improvement of 7% in area under the ROC curve over the state-of-the-art. Right plot in Figure 8 is obtained by comparing pixel-wise abnormality detections with ground-truth masks. A frame is considered abnormal if at least 40% of all truly abnormal pixels are detected. Our method shows a significant improvement over the state-of-the-art (32% in area under the ROC curve), which is a consequence of better localization properties of the parsing approach.
 |
 |
Resources
Complete pixel-wise groundtruth for the UCSD Ped1 datasettar.gz