Category-Level object detection has a crucial need for informative object representations. This demand has led to feature descriptors of ever increasing dimensionality like co-occurrence statistics and self-similarity. In this paper we propose a new object representation based on curvature self-similarity that goes beyond the currently popular approximation of objects using straight lines.
Motivation
The vision community has now broadly adopted the theme of gradient histograms. In effect, this results in a straight line approximation of object boundaries since local regions are described by a histogram over a discrete set of edge orientations that they contain. Edge orientations are a good representation for straight line objects (e.g. the shelf on the left), however objects are usually curved (e.g. objects on the right).

The examples below show that one cannot distinguish a smooth curve from one with corners or from a set of differently oriented lines in an arbitrary configuration based only on histograms of oriented gradients

In our earlier work [1] we extended the modeling of object boundary contours beyond the widely used edge orientation histograms by utilizing curvature information to overcome the drawbacks of straight-line approximations. However, the co-occurrence of contour curvature can provide even more information about the object boundary and thus increases the distinctiveness (as shown in the examples below). By computing co-occurrences between discriminatively curved boundaries we build a curvature self-similarity descriptor that provides a more detailed and accurate object description.

However, like all descriptors using second order statistics, ours also exhibits a high dimensionality. Although improving discriminability, the high dimensionality becomes a critical issue due to lack of generalization ability and curse of dimensionality. Given only a limited amount of training data, even sophisticated learning algorithms such as the popular kernel methods are not able to suppress noisy or superfluous dimensions of such high-dimensional data. Consequently, there is a natural need for feature selection when using present-day informative features and, particularly, curvature self-similarity. We therefore suggest an embedded feature selection method for SVMs that reduces complexity and improves generalization capability of object models.
Method
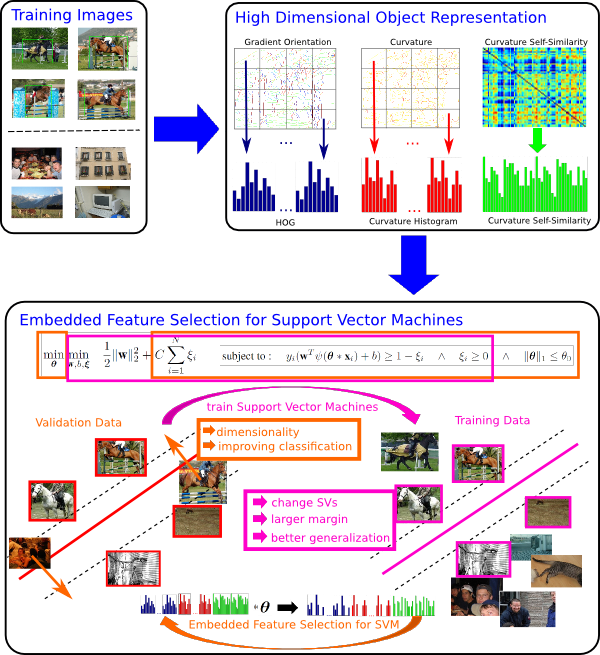
Embedded Feature Selection for SVM
Feature selection methods can be categorized into filters, wrappers and embedded methods. Contrary to filters and wrappers embedded feature selection methods incorporate feature selection as a part of the learning process. The focus of this paper is on embedded feature selection methods for SVMs, since most state-of-the-art detection systems use SVM as a classifier. To directly integrate feature selection into the learning process of SVMs sparsity can be enforced on the model parameter $w$ . Contrary to linear SVM enforcing sparsity on the model parameter $w$ does reduce dimensionality for non-linear kernel functions in the higher dimensional kernel space rather than in the number of input features. In our work we are following the concept of embedded feature selection and therefore include the feature selection parameter $\theta$ directly in the SVM classifier, where $\{(x_i, y_i)\}$ for $1 \le i \le N$ are the training data with labels $y_i \in \{-1, +1\}$. The corresponding optimization problem can be expressed in the following way:
$$\min_{\theta, w, b, \xi} \frac12{\parallel w\parallel_2^2} + C \sum_{i=0}^n \xi_i$$ subject to: $$y_i(w^T \psi (\theta * x_i) + b) \ge 1 - \xi_i \land \xi_i \ge 0 \land {\parallel\theta\parallel}_1 \le {\theta}_0$$where $K(x, z) := \psi(x) . \psi(z)$ is the SVM kernel function. The function $\psi(x)$ is typically unknown and represents the mapping of the feature vector $x$ into a higher dimensional space. We enforce sparsity of the feature selection parameter $\theta$ by the last constraint, which restricts the L1-norm of $\theta$ by a constant ${\theta}_0$. Due to the complexity of this problem we propose to solve two simpler problems iteratively. First we split the training data into a training and validation set. Now we optimize the problem according to $w$ and $b$ for fixed selection parameter ${\theta}_0$ using a standard SVM algorithm on the training set. This Parameter $\theta$ is optimized in a second optimization step on the validation to reduce dimensionality of the feature vector and improve classification performance.
Representing Curvature Self-Similarity
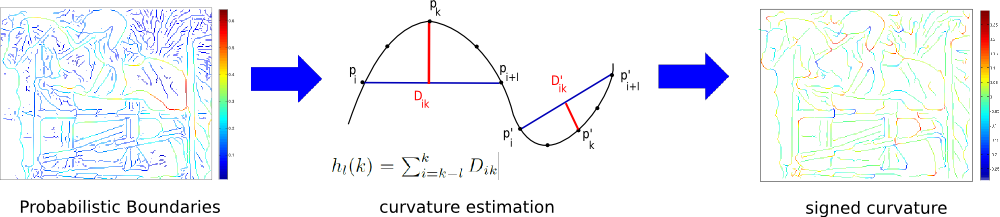
We propose a new holistic self-similarity representation based on curvature. As a first step we extract the curvature information and the corresponding 360 degree orientation of all edge pixels in the image. To estimate the curvature we use the distance accumulation method of Han et al. [4], which accurately approximates the curvedness along given 2D line segments. Let $B := \{ p_0, p_1, p_2, ... , p_{N - 1}\}$ be a set of consecutive boundary points, representing one line segment. The perpendicular distance $D_{ik}$ is computed from a chord to the point $p_k$, using the euclidean distance. The distance accumulation for point $p_k$ is the sum $ h-l(k) = \sum_{i = k - l}^k D_{ik}$. The distance is positive if $p_k$ is on the left-hand side of the chord, and negative otherwise. The describe procedure is summarized in the figure below.
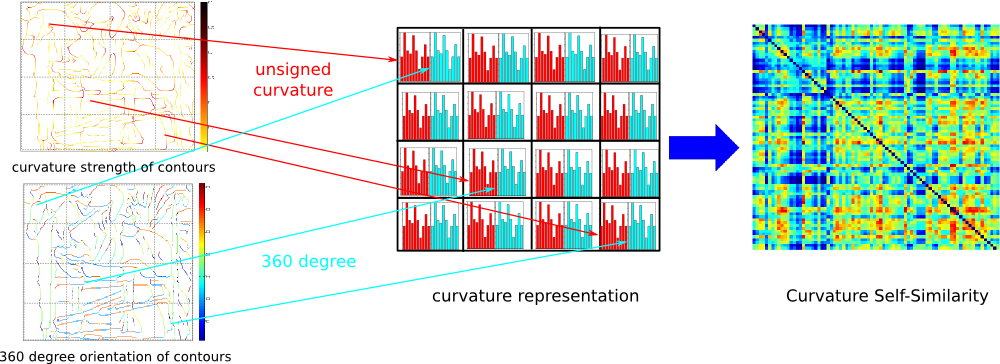
To describe complex objects it is not sufficient to build a self-similarity descriptor soley based on curvature information, since self-similarity of curvature leaves open many ambiguities. To resolve these ambiguities we add 360 degree orientation information to get a more accurate descriptor. To get the 360 degree orientation information we compute the gradient of the edge image and extend the resulting 180 degree gradient orientation to a 360 degree orientation using the sign of the curvature. Next we divide the image into non-overlapping pixel cells and build histograms over the unsigned curvature values and the 360 degree orientation in each cell. The two histograms are concatenated in each cell and all pairwise similarities between the cells are computed using histogram intersection as a comparison measure. The figure below visualizes the described procedure.
The examples below show the original images along with their curvature self-similarity matrices displaying the similarity between all pairs of curvature histogram cells. While curvature self-similarity descriptor is similar for the same object category it looks quite different to other object categories.

Results
We evaluate our curvature self-similarity descriptor in combination with the suggested embedded dimensionality reduction algorithm for the object detection task on the PASCAL dataset. To show the individual strengths of these two contributions we need to perform a number of evaluations. Since this is not supported by the PASCAL VOC 2011 evaluation server we follow the best practice guidelines and use the VOC 2007 dataset. Our experiments show, that curvature self-similarity is providing complementary information to straight lines, while our feature selection algorithm is further improving performance by fulfilling its natural need for dimensionality reduction.
The common basic concept shared by many current detection systems are high-dimensional, holistic representations learned with a discriminative classifier, mostly an SVM. In particular the combination of HOG and SVM constitutes the basis of many powerful recognition systems and it has laid the foundation for numerous extensions like, part based models, variations of the SVM classifier and approaches utilizing context information. These systems rely on high-dimensional holistic image statistics primarily utilizing straight line approximations. In this paper we explore a orthogonal direction to these extensions and focus on how one can improve on the basic system by extending the straight line representation of HOG to a more discriminative description using curvature self-similarity. At the same time our aim is to reduce the dimensionality of such high-dimensional representations to decrease the complexity of the learning procedure and to improve generalization performance.
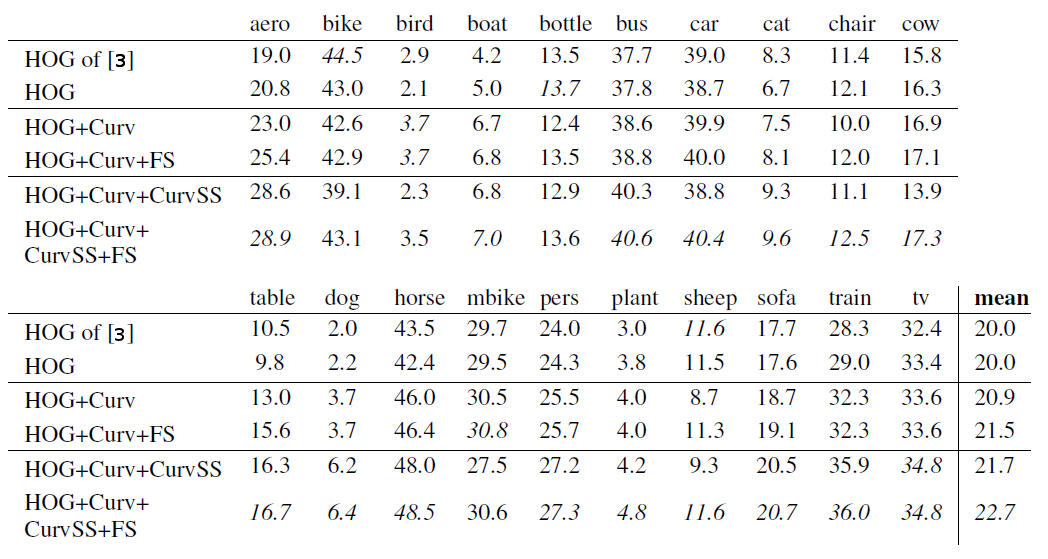
We provide a structured evaluation of the parts of our final object detection system. We use the HOG of Felzenswalb et al. [2,3] as baseline system, since it is the basis fo many powerful object detection systems. The table below shows the detection performance in terms of average precision of the HOG baseline system, HOG and curvature (Curv) before and afer discarding noisy dimensions using our feature selection method (FS) and our final detection system consisting of HOG, curvature (Curv), the suggested curvature self-similarity (CurvSS) with and without feature selection (FS) on the PASCAL VOC 2007 dataset. Note, that we use all data points to compute the average precision as it is specified by the default experimental protocol since VOC 2010 development kit. This yields lower but more accurate average precision measurements.