| Title | Self-supervised Learning of Pose Embeddings from Spatiotemporal Relations in Videos |
| Publication Type | Conference Paper |
| Year of Publication | 2017 |
| Authors | Sümer, Ö, Dencker, T, Ommer, B |
| Conference Name | Proceedings of the IEEE International Conference on Computer Vision (ICCV) |
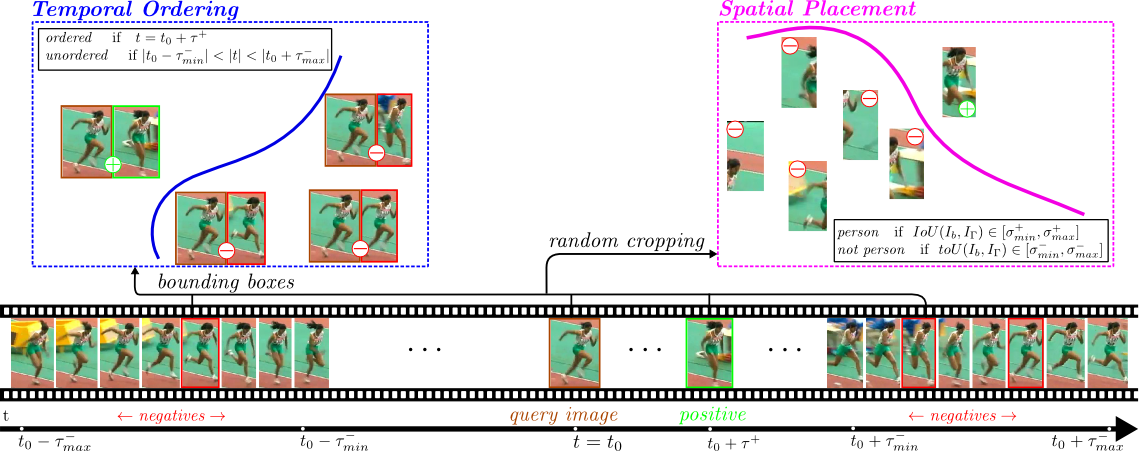
| Abstract | Human pose analysis is presently dominated by deep convolutional networks trained with extensive manual annotations of joint locations and beyond. To avoid the need for expensive labeling, we exploit spatiotemporal relations in training videos for self-supervised learning of pose embeddings. The key idea is to combine temporal ordering and spatial placement estimation as auxiliary tasks for learning pose similarities in a Siamese convolutional network. Since the self-supervised sampling of both tasks from natural videos can result in ambiguous and incorrect training labels, our method employs a curriculum learning idea that starts training with the most reliable data samples and gradually increases the difficulty. To further refine the training process we mine repetitive poses in individual videos which provide reliable labels while removing inconsistencies. Our pose embeddings capture visual characteristics of human pose that can boost existing supervised representations in human pose estimation and retrieval. We report quantitative and qualitative results on these tasks in Olympic Sports, Leeds Pose Sports and MPII Human Pose datasets. |
| Citation Key | 6193 |