


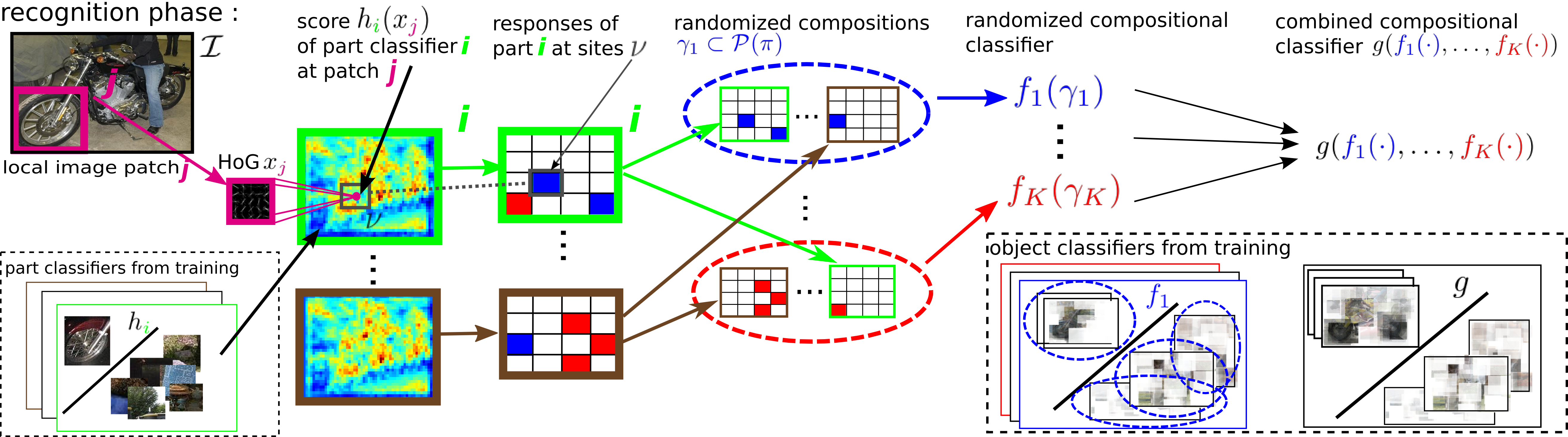
A main theme in object detection are currently discriminative part-based models. The powerful model that combines all parts is then typically only feasible for few constituents, which are in turn iteratively trained to make them as strong as possible. We follow the opposite strategy by randomly sampling a large number of instance specific part classifiers. Due to their number, we cannot directly train a powerful classifier to combine all parts. Therefore, we randomly group them into fewer, overlapping compositions that are trained using a maximum-margin approach. In contrast to the common rationale of compositional approaches, we do not aim for semantically meaningful ensembles. Rather we seek randomized compositions that are discriminative and generalize over all instances of a category.
Processing Pipeline
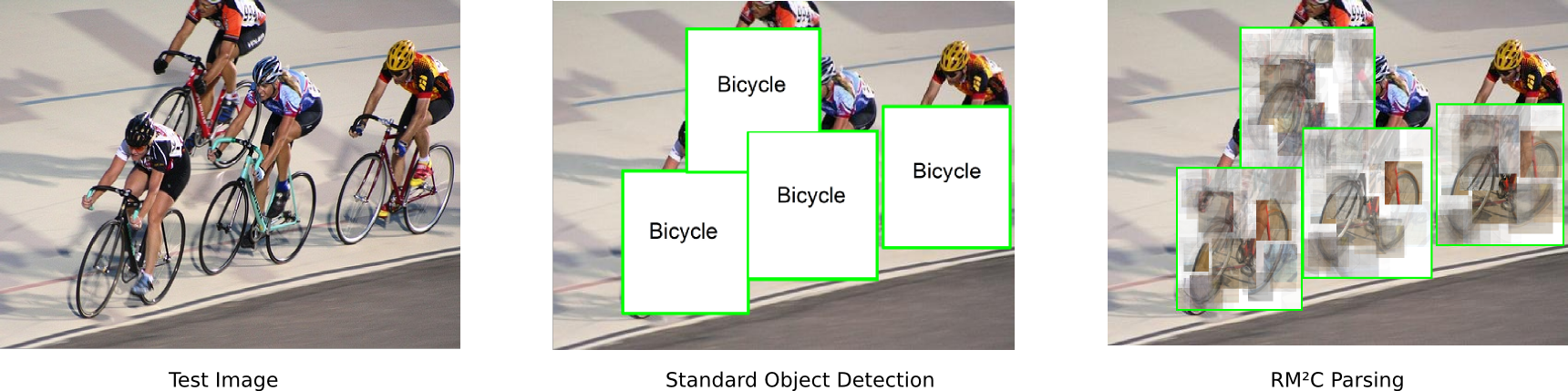
Object Parsing
Standard Object Detection provides a the Bounding Box of and the class label of an object. Our approach not only localizes objects in cluttered scenes, but also explains them by parsing with compositions and their constituent parts. Compositions are activated according to the classification function 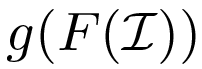 and compositions in turn activate parts
and compositions in turn activate parts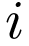 (we plot the corresponding positive training patch
(we plot the corresponding positive training patch 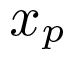 ) by weighting them according to the decision function
) by weighting them according to the decision function 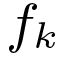 .
.
Experimental Results
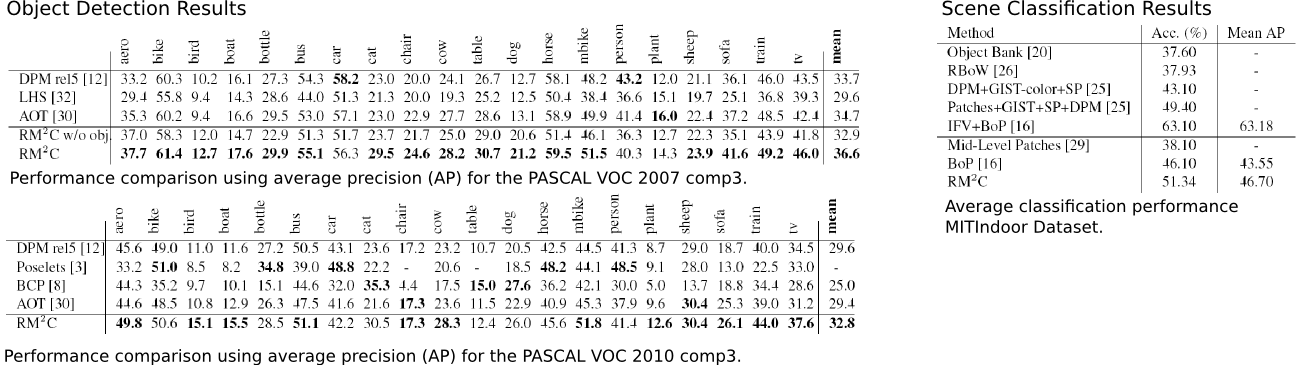 Precision-Recall Curves for PASCAL VOC 2007
Precision-Recall Curves for PASCAL VOC 2007
Downloads
- Pretrained part models :
- Supplementary
- Poster