





RESEARCH HIGHLIGHTS 
The Rich Scene Model (ERC Consolidator Grant)
Given a sequence of images the goal is to recover a rich, detailed representation of the 3D world, ranging from physical to semantical aspects. To achieve this we investigate new ways to combine feature learning, modelling, physical laws, and optimization in large-scale discrete-continuous-valued probabilistic graphical model.



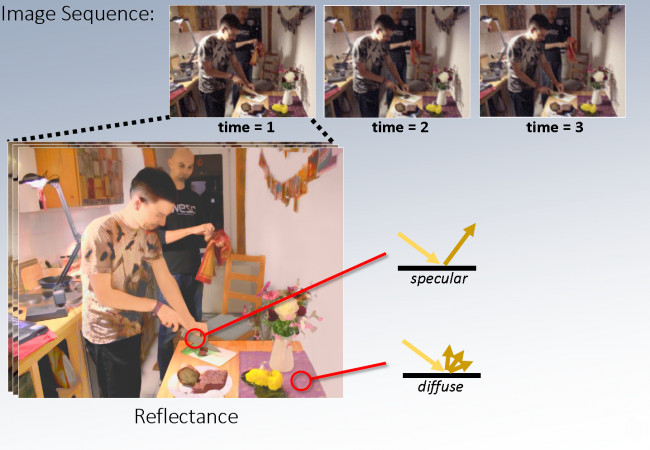
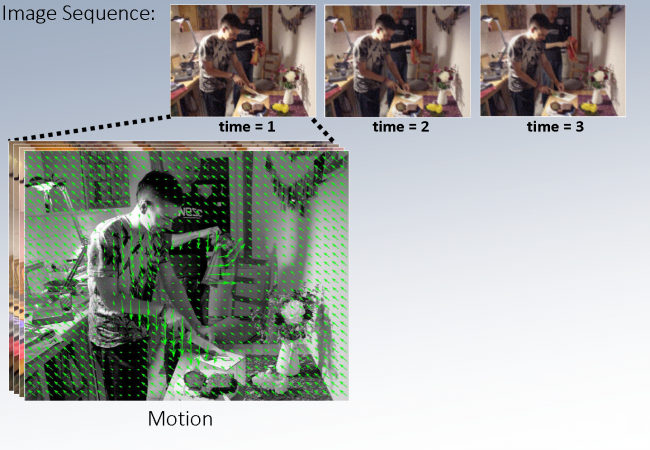
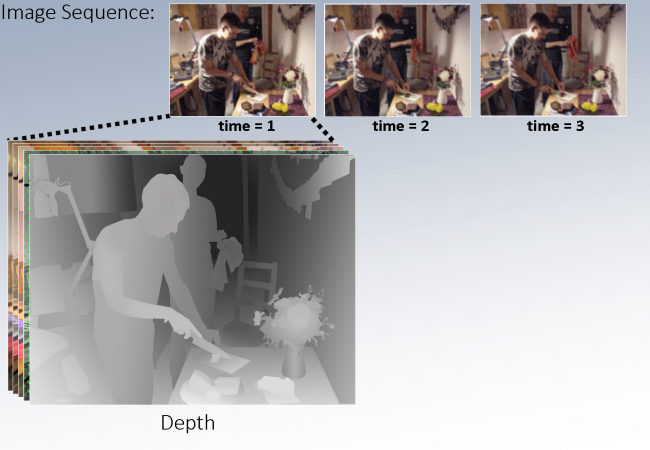
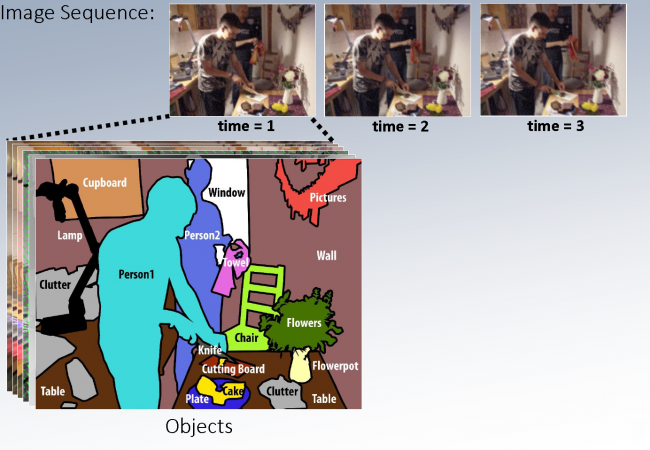

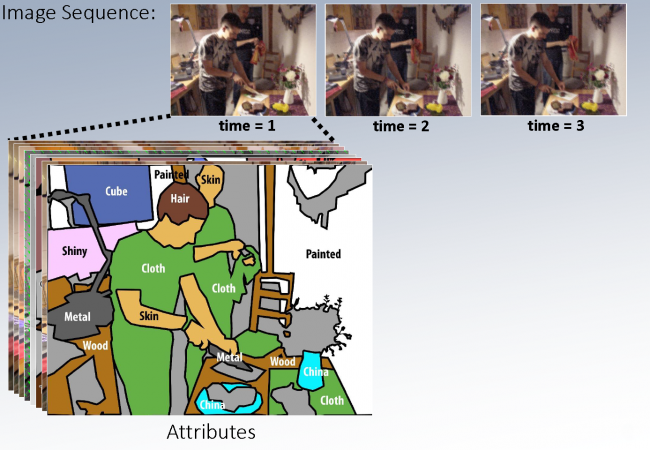
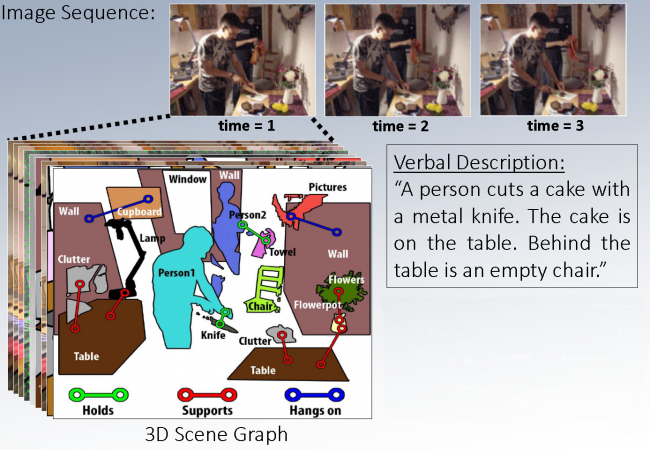
Selected Events
- Three papers accepted to ICCV ’21, on Graph Matching; Self-supervised Object Detection; and Camera Localization
 Carsten Rother among 9 most influential CV scholars in Europe
Carsten Rother among 9 most influential CV scholars in Europe Our excellent cluster “Structures” – where ML is used to find structures in data and the physical world – got funded by DFG
Our excellent cluster “Structures” – where ML is used to find structures in data and the physical world – got funded by DFG- Three papers accepted to ACCV on: Geometric Image Synthesis; Deep Object Co-segmentation; 6D Object Pose Estimation
 Check out our latest Camera Localization results
Check out our latest Camera Localization results