
Projects:
Expert Sample Consensus Applied to Camera Re-Localization (2019)
Learning Less is More – 6D Camera Localization via 3D Surface Regression (2018)
DSAC – Differentiable RANSAC for Camera Localization (2017)
Global Hypothesis Generation for 6D Object Pose Estimation (2017)
PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning (2017)
Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image (2016)
Learning Analysis-by-Synthesis for 6D Pose Estimation in RGB-D Images (2015)
Pose Estimation of Kinematic Chain Instances via Object Coordinate Regression (2015)
6-DOF Model Based Tracking via Object Coordinate Regression (2014)
Learning 6D Object Pose Estimation using 3D Object Coordinates (2014)
Expert Sample Consensus Applied to Camera Re-Localization:
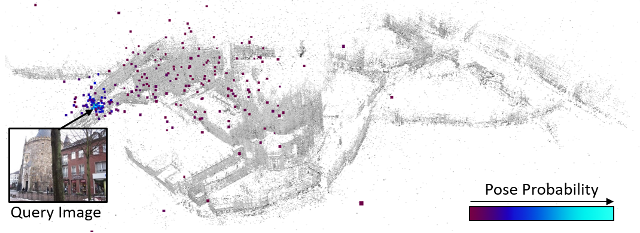
Authors:
Eric Brachmann, Carsten Rother
Abstract:
Fitting model parameters to a set of noisy data points is a common problem in computer vision. In this work, we fit the 6D camera pose to a set of noisy correspondences between the 2D input image and a known 3D environment. We estimate these correspondences from the image using a neural network. Since the correspondences often contain outliers, we utilize a robust estimator such as Random Sample Consensus (RANSAC) or Differentiable RANSAC (DSAC) to fit the pose parameters. When the problem domain, e.g. the space of all 2D-3D correspondences, is large or ambiguous, a single network does not cover the domain well. Mixture of Experts (MoE) is a popular strategy to divide a problem domain among an ensemble of specialized networks, so called experts, where a gating network decides which expert is responsible for a given input. In this work, we introduce Expert Sample Consensus (ESAC), which integrates DSAC in a MoE. % In this work, we show how to . In particular, the gating network distributes a given budget of model hypotheses among experts according to its own uncertainty. The final model parameters are then chosen according to sample consensus. Our main technical contribution is an efficient method to train ESAC jointly and end-to-end. We demonstrate experimentally that ESAC handles two real-world problems better than competing methods, i.e. scalability and ambiguity. We apply ESAC to fitting simple geometric models to synthetic images, and to camera re-localization for difficult, real datasets.
Poster:

Results:
Code:
ESAC for camera re-localization: https://github.com/vislearn/esac/
Publication:
E. Brachmann, C. Rother, “Expert Sample Consensus Applied to Camera Re-Localization”, ICCV 2019. [pdf]
Learning Less is More – 6D Camera Localization via 3D Surface Regression:
Authors:
Eric Brachmann, Carsten Rother
Abstract:
Popular research areas like autonomous driving and augmented reality have renewed the interest in image-based camera localization. In this work, we address the task of predicting the 6D camera pose from a single RGB image in a given 3D environment. With the advent of neural networks, previous works have either learned the entire camera localization process, or multiple components of a camera localization pipeline. Our key contribution is to demonstrate and explain that learning a single component of this pipeline is sufficient. This component is a fully convolutional neural network for densely regressing so-called scene coordinates, defining the correspondence between the input image and the 3D scene space. The neural network is prepended to a new end-to-end trainable pipeline. Our system is efficient, highly accurate, robust in training, and exhibits outstanding generalization capabilities. It exceeds state-of-the-art consistently on indoor and outdoor datasets. Interestingly, our approach surpasses existing techniques even without utilizing a 3D model of the scene during training, since the network is able to discover 3D scene geometry automatically, solely from single-view constraints.
Overview:
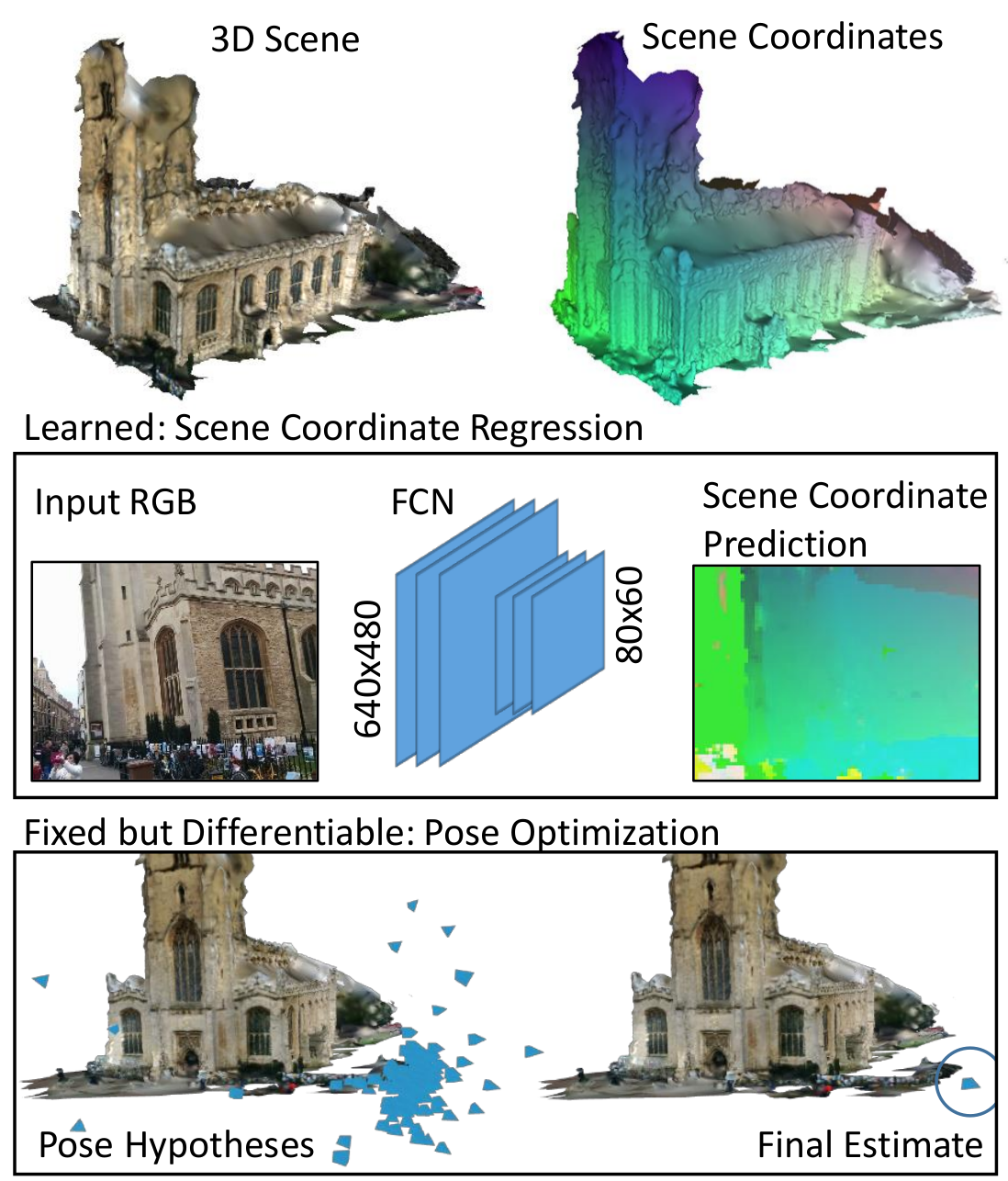
System Overview. Given an RGB image, we estimate the 6D camera pose in two stages. Firstly, a fully convolutional network (FCN) regresses 3D scene coordinates (XYZ mapped to RGB for visualization). This CNN is the only learnable component of our system. Secondly, the system optimizes the pose by sampling a pool of hypotheses, scoring them using a soft inlier count, selecting one according to the scores, and refining it as the final estimate. The second stage contains no learnable parameters but is fully differentiable.
Poster:

Results:
Code:
We provide the source code of our method on Github. We also provide a data package with trained models. Please cite the paper below if you use the code or parts of it in your own research.
Publication:
E. Brachmann, C. Rother, “Learning Less is More – 6D Camera Localization via 3D Surface Regression”, CVPR 2018. [pdf]
DSAC – Differentiable RANSAC for Camera Localization:
Authors:
Eric Brachmann¹, Alexander Krull¹, Sebastian Nowozin², Jamie Shotton², Frank Michel¹, Stefan Gumhold¹, Carsten Rother¹
¹ TU Dresden, ² Microsoft
Abstract:
RANSAC is an important algorithm in robust optimization and a central building block for many computer vision applications. In recent years, traditionally hand-crafted pipelines have been replaced by deep learning pipelines, which can be trained in an end-to-end fashion. However, RANSAC has so far not been used as part of such deep learning pipelines, because its hypothesis selection procedure is non-differentiable. In this work, we present two different ways to overcome this limitation. The most promising approach is inspired by reinforcement learning, namely to replace the deterministic hypothesis selection by a probabilistic selection for which we can derive the expected loss w.r.t. to all learnable parameters. We call this approach DSAC, the differentiable counterpart of RANSAC. We apply DSAC to the problem of camera localization, where deep learning has so far failed to improve on traditional approaches. We demonstrate that by directly minimizing the expected loss of the output camera poses, robustly estimated by RANSAC, we achieve an increase in accuracy. In the future, any deep learning pipeline can use DSAC as a robust optimization component.
Overview:

Differentiable Camera Localization Pipeline. Given an RGB image, we let a CNN with parameters w predict 2D-3D cor-
respondences, so called scene coordinates. From these, we sample minimal sets of four scene coordinates and create a pool of
hypotheses h. For each hypothesis, we create an image of reprojection errors which is scored by a second CNN with parameters v. We
select a hypothesis probabilistically according to the score distribution. The selected pose is also refined.
Poster:

Code:
We provide the source code of our method on Github. We also provide trained models for the 7Scenes dataset: Models.
We additionally provide a PyTorch example of using DSAC for fitting lines.
Please cite the paper below if you use the code or parts of it in your own research.
Publication:
E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, C. Rother, “DSAC – Differentiable RANSAC for Camera Localization”, CVPR 2017. [pdf]
Global Hypothesis Generation for 6D Object Pose Estimation:
Authors:
Frank Michel, Alexander Kirillov, Eric Brachmann, Alexander Krull, Stefan Gumhold, Bogdan Savchynskyy, Carsten Rother
Abstract:
This paper addresses the task of estimating the 6D pose of a known 3D object from a single RGB-D image. Most modern approaches solve this task in three steps: i) Compute local features; ii) Generate a pool of pose-hypotheses; iii) Select and refine a pose from the pool. This work focuses on the second step. While all existing approaches generate the hypotheses pool via local reasoning, e.g. RANSAC or Hough-voting, we are the first to show that global reasoning is beneficial at this stage. In particular, we formulate a novel fully-connected Conditional Random Field (CRF) that outputs a very small number of pose-hypotheses. Despite the potential functions of the CRF being non-Gaussian, we give a new and efficient two-step optimization procedure, with some guarantees for optimality. We utilize our global hypotheses generation procedure to produce results that exceed state-of-the-art for the challenging “Occluded Object Dataset”.
Data:
We provide additional annotations of occluded objects for the dataset of [1] that we used for hyper-parameter tuning. This data is similar to the Occluded Object Dataset of our ECCV14 paper. You can download the new annotations here. Please cite our publication below if you use this data in your own research.
Publication:
F. Michel, A. Kirillov, E. Brachmann, A. Krull, S. Gumhold, B. Savchynskyy, C. Rother, “Global Hypothesis Generation for 6D Object Pose Estimation”, CVPR 2017. [pdf]
References:
[1] S. Hinterstoisser, V. Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige, N. Navab, “Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes”, ACCV 2012
PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning:
Authors:
Alexander Krull¹, Eric Brachmann¹, Sebastian Nowozin², Frank Michel¹, Jamie Shotton², Carsten Rother¹
¹ TU Dresden, ² Microsoft
Abstract:
State-of-the-art computer vision algorithms often achieve efficiency by making discrete choices about which hypotheses to explore next. This allows allocation of computational resources to promising candidates, however, such decisions are non-differentiable. As a result, these algorithms are hard to train in an end-to-end fashion. In this work we propose to learn an efficient algorithm for the task of 6D object pose estimation. Our system optimizes the parameters of an existing state-of-the art pose estimation system using reinforcement learning, where the pose estimation system now becomes the stochastic policy, parametrized by a CNN. Additionally, we present an efficient training algorithm that dramatically reduces computation time. We show empirically that our learned pose estimation procedure makes better use of limited resources and improves upon the state-of-the-art on a challenging dataset. Our approach enables differentiable end-to-end training of complex algorithmic pipelines and learns to make optimal use of a given computational budget.
Publication:
A. Krull, E. Brachmann, S. Nowozin, F. Michel, J. Shotton, C. Rother, “PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning”, CVPR 2017. [pdf]
Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image:
Authors:
Eric Brachmann, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Abstract:
In recent years, the task of estimating the 6D pose of object instances and complete scenes, \ie camera localization, from a single input image has received considerable attention. Consumer \mbox{RGB-D} cameras have made this feasible, even for difficult, texture-less objects and scenes. In this work, we show that a single RGB image is sufficient to achieve visually convincing results. Our key concept is to model and exploit the uncertainty of the system at all stages of the processing pipeline. The uncertainty comes in the form of continuous distributions over 3D object coordinates and discrete distributions over object labels. We give three technical contributions. Firstly, we develop a regularized, auto-context regression framework which iteratively reduces uncertainty in object coordinate and object label predictions. Secondly, we introduce an efficient way to marginalize object coordinate distributions over depth. This is necessary to deal with missing depth information. Thirdly, we utilize the distributions over object labels to detect multiple objects simultaneously with a fixed budget of RANSAC hypotheses. We tested our system for object pose estimation and camera localization on commonly used data sets. We see a major improvement over competing systems.
Spotlight Video:
Results:

(Left) Result of our method. The pose of the lamp is estimated sufficiently well for augmented realty. (Right) Result of a state-of-the-art system [Krull et al., ICCV 2015] that uses an RGB-D input image. The pose is less well suited for augmented reality.

Pose estimation from an RGB image. Four objects, partially overlaid with 3D models with the estimated pose.
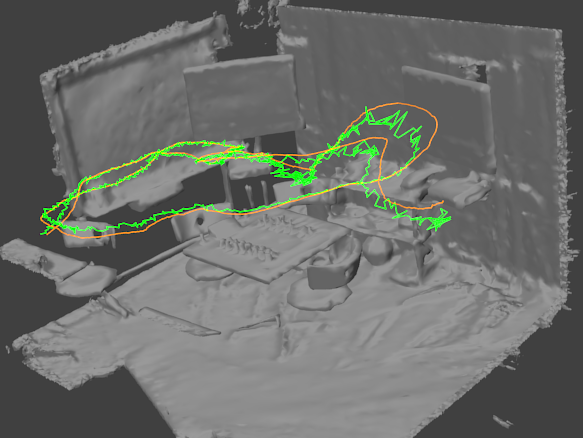
Camera localization results. We show the estimated camera path (green) for one complete image sequence. The ground truth camera path (orange) is also shown for comparison.
Poster:

Code:
We provide the source code of our method under the BSD License. The following package contains code, a short documentation and configuration files with parameter settings used in the experiments of the paper: CVPR16 Code
In order to test the code, we provide the follow dummy data package which contains some images of the dataset of Hinterstoisser et al. in the format our code requires: Dummy Data (for the original, complete dataset visit: http://campar.in.tum.de/Main/StefanHinterstoisser)
Please cite the paper below if you use the code or parts of it in your own research.
Publication:
E. Brachmann, F. Michel, A. Krull, M. Y. Yang, S. Gumhold, C. Rother, “Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image”, CVPR 2016. [pdf][supplement]
Learning Analysis-by-Synthesis for 6D Pose Estimation in RGB-D Images:
Authors:
Alexander Krull, Eric Brachmann, Frank Michel, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Abstract:
Analysis-by-synthesis has been a successful approach for many tasks in computer vision, such as 6D pose estimation of an object in an RGB-D image which is the topic of this work. The idea is to compare the observation with the output of a forward process, such as a rendered image of the object of interest in a particular pose. Due to occlusion or complicated sensor noise, it can be difficult to perform this comparison in a meaningful way. We propose an approach that “learns to compare”, while taking these difficulties into account. This is done by describing the posterior density of a particular object pose with a convolutional neural network (CNN) that compares observed and rendered images. The network is trained with the maximum likelihood paradigm. We observe empirically that the CNN does not specialize to the geometry or appearance of specific objects. It can be used with objects of vastly different shapes and appearances, and in different backgrounds. Compared to state-of-the-art, we demonstrate a significant improvement on two different datasets which include a total of eleven objects, cluttered background, and heavy occlusion.
Spotlight Video:
Results:
 |
|
Publication:
A. Krull, E. Brachmann, F. Michel, M. Ying Yang, S. Gumhold, C. Rother: “Learning Analysis-by-Synthesis for 6D Pose Estimation in RGB-D Images“,Supplementary Material, ICCV 2015.
Pose Estimation of Kinematic Chain Instances via Object Coordinate Regression:
Authors:
Frank Michel, Alexander Krull, Eric Brachmann, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Abstract:
In this paper, we address the problem of one shot pose estimation of articulated objects from an RGB-D image. In particular, we consider object instances with the topology of a kinematic chain, i.e. assemblies of rigid parts connected by prismatic or revolute joints. This object type occurs often in daily live, for instance in the form of furniture or electronic devices. Instead of treating each object part separately we are using the relationship between parts of the kinematic chain and propose a new minimal pose sampling approach. This enables us to create a pose hypothesis for a kinematic chain consisting of K parts by sampling K 3D-3D point correspondences. To asses the quality of our method, we gathered a large dataset containing four objects and 7000+ annotated RGB-D frames. On this dataset we achieve considerably better results than a modified state-of-the-art pose estimation system for rigid objects.
Results:
 |
 |
 |
 |
Dataset:
We created a dataset of four different kind of kinematic chains which differ in the number and type of joints. The objects are a laptop with a hinged lid (one revolute joint), a cabinet with a door and drawer (one revolute and one prismatic joint), a cupboard with one movable drawer (one prismatic joint) and a toy train consisting of four parts (four revolute joints). It can be downloaded here. See the readme for more information.
Publication:
F. Michel, A. Krull, E. Brachmann, M. Y. Yang, S. Gumhold, C. Rother: “Pose Estimation of Kinematic Chain Instances via Object Coordinate Regression“, Supplementary Material, Extended Abstract, BMVC 2015.
6-DOF Model Based Tracking via Object Coordinate Regression:
Authors:
Alexander Krull, Frank Michel, Eric Brachmann, Stefan Gumhold, Stephan Ihrke, Carsten Rother
Abstract:
This work investigates the problem of 6-Degrees-Of-Freedom (6-DOF) object tracking from RGB-D images, where the object is rigid and a 3D model of the object is known. As in many previous works, we utilize a Particle Filter (PF) framework. In order to have a fast tracker, the key aspect is to design a clever proposal distribution which works reliably even with a small number of particles. To achieve this we build on a recently developed state-of-the-art system for single image 6D pose estimation of known 3D objects, using the concept of so-called 3D object coordinates. The idea is to train a random forest that regresses the 3D object coordinates from the RGB-D image. Our key technical contribution is a two-way procedure to integrate the random forest predictions in the proposal distribution generation. This has many practical advantages, in particular better generalization ability with respect to occlusions, changes in lighting and fast-moving objects. We demonstrate experimentally that we exceed state-of-the-art on a given, public dataset. To raise the bar in terms of fast-moving objects and object occlusions, we also create a new dataset, which will be made publicly available.
Results:
Dataset:
The dataset can be downloaded here. See the readme for more information.
Publication:
A. Krull, F. Michel, E. Brachmann, S. Gumhold, S. Ihrke, C. Rother: “6-DOF Model Based Tracking via Object Coordinate Regression“, Supplementary Material, ACCV 2014.
Learning 6D Object Pose Estimation using 3D Object Coordinates:
Authors:
Eric Brachmann, Alexander Krull, Frank Michel, Stefan Gumhold, Jamie Shotton, Carsten Rother
Abstract:
This work addresses the problem of estimating the 6D Pose of specific objects from a single RGB-D image. We present a flexible approach that can deal with generic objects, both textured and texture-less. The key new concept is a learned, intermediate representation in form of a dense 3D object coordinate labelling paired with a dense class labelling. We are able to show that for a common dataset with texture-less objects, where template-based techniques are suitable and state of the art, our approach is slightly superior in terms of accuracy. We also demonstrate the benefits of our approach, compared to template-based techniques, in terms of robustness with respect to varying lighting conditions. Towards this end, we contribute a new ground truth dataset with 10k images of 20 objects captured each under three different lighting conditions. We demonstrate that our approach scales well with the number of objects and has capabilities to run fast.
Overview:
Results:
Datasets:
We make available our own dataset, background images we used during training, and additional annotations for the dataset of Hinterstoisser et al.[1].
20 Objects Light Dataset:
RGB-D images and ground truth poses for 20 textured and texture-less objects, each recorded under three different lighting conditions. See the readme for more information. We provide the dataset under the CC BY-SA 4.0 license.
Background Dataset:
This dataset contains RGB-D images of different, cluttered office backgrounds. They were used to represent the background class
when training our random forest. See the readme for more information.
Occlusion Dataset:
NOTE: Below you find the version of the occlusion dataset as it was used in our ECCV14 paper. However, we released a reworked version of the dataset as part of the BOP Challenge. The reworked version contains all data (images, poses, 3D models of objects) and some annotation errors have been corrected. We advise to use the reworked version of the dataset.
This dataset contains additional annotations of occluded objects for the dataset of Hinterstoisser et al.[1]. See the readme for more information. We provide the dataset under the CC BY-SA 4.0 license.
Software:
We provide pre-compiled binaries for Linux (Ubuntu 12.04). See the readme for more information.
Poster:

Publication:
E. Brachmann, A. Krull, F. Michel, S. Gumhold, J. Shotton, and C. Rother: “Learning 6D Object Pose Estimation using 3D Object Coordinates“, Supplementary Material, ECCV 2014.
References:
[1] S. Hinterstoisser, V. Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige, N. Navab, “Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes”, ACCV 2012